28 Jan Lyra: Automatic subtitle placing at 96% of accuracy
With hundreds of millions of subscribers globally, video streaming companies (Amazon Prime Video, Netflix, Hulu) have to keep the pace. For example, the video streaming giant Netflix, with 139 millions users, serves around 100 millions hours a day on TV screens (10% screen share in the US), followed by Prime Video with 90 millions users and Hulu with 23 millions. 2017 was the first year in history in which watching downloaded or streamed video was more popular than watching traditional TV among U.S. consumers aged 45 and under.
But this is not an article on ratings, market share or cash flow. What is most impressive (at least for us) is the quantity of video content being produced, ingested and served by these platform. Only in 2018 it was expected that Netflix will release 700 original TV shows and 80 original films.
But along the films themselves there is more. A primary asset of every TV program are language subtitles  . With presence in 190 countries, language options had raised to as much as 20 languages, and hearing impaired versions as well. According to video streaming companies themselves:
. With presence in 190 countries, language options had raised to as much as 20 languages, and hearing impaired versions as well. According to video streaming companies themselves:
Timed text files are needed not only to translate foreign language dialogue, and provide the deaf and hard of hearing access to content, but also to allow one to watch content in a noisy environment. With the rapid growth of mobile devices, living rooms are no longer needed to enjoy your favorite film or television show. Subtitles allow members to enjoy content without the need for silence or headphones. Timed text files are paramount not only to the service, but also for the consumption of media in a world without the living room as the primary center of entertainment. [….]
Our members simply want an effortless experience, and this means that they will be able to read subtitles or closed captions without being reminded that they are reading. Awkward language pulls you out of the viewing experience instead of supporting the experience
A complex workflow
One may think that subtitling is a simple process: just someone watching the movie and writing down what is being said. Far from that: subtitling protocols have dozens of pages, with particularities for each language and information at the level of a single character. Linguists, translators, sinchronisers and quality checkers are part of a complex work flow.
Video platforms partner with companies around the world to generate these subtitle assets. High standards are required to work with them: acceptance rates close to 99% have to be maintained. This doesn’t mean that 99% of subtitles are correct but that 99% of the programs delivered by a partner have zero errors.
Developing Lyra
And here is where Zowl Labs (http://www.zowllabs.com) comes into play. Some months ago we were contacted by the guys at Oxobox (https://oxobox.tv), one of the top-tired certified subtitling service providers in the world, with a great challenge. How can we make this workflow more efficient, more precise and more predictable using artificial intelligence. In other words, can we automatize any of the stages of the subtitling process?
You may guess our answer and some months after we were delivering a production ready version of Lyra: an automatic subtitle placing solution. And this is how we did it.
Stating the problem: Usually we face with clients that come and say “I have an idea, we can use AI. Let’s put a camera!”. Our immediate reaction is to say “why?”. The answer is often unclear… Though it was not the case with Oxobox (they were quite clear on what they wanted), one of the main challenges for us was to understand the workflow for generating a subtitle asset and where artificial intelligence (in the form of a machine learning system) could help. We got material from them, we studied their own platform and together wrote down the requirements. The whole boiled down to the following: in a first stage Lyra (at that time it was nameless) would process an audio clip extracted from a program and output where in time a subtitle should be inserted. This is called a template and involves determining the start point, duration and endpoint of a time segment that corresponds to someone speaking. The complexity: these segments must comply with their protocol strictly. Not too long, not too short and with precision to the millisecond.
Why the name Lyra? The name comes from the lyrebird, an Australian species most notable for its ability to listen the environment and mimic sounds.
Data: We all know that getting good data is one of the key aspects of a machine learning system. In this case we already had several hours of programs with human-generated subtitles. With the help of Oxobox we constructed a dataset consisting of 80 hours with 87 video clips, 3 different languages (English, Spanish and Portuguese) and we explicitly requested the set to be sufficiently heterogeneous, that is, we expected to have different types of contents (films of different category, TV series, documentaries, kids programs). The ground-truth were subtitle text files with timing information. Though it was relatively easy to get the data, the downside is that subtitling is sometimes a subjective task: where to start, where to end, how to divide phrases, how to avoid scene spoiling. No two subtitling jobs are equal… and we had to deal with that.
The algorithm
Lyra is basically a set of software modules to train, learn, deploy and evaluate machine learning models for automatic subtitling placing from audio files. It uses deep learning technology based on a custom Convolutional Neural Network (CNN). First we extract time-frequency features from audio files and this is the information that is used as an input to the neural network to train the system. At the output the algorithm predicts if a subtitle should be active or not.
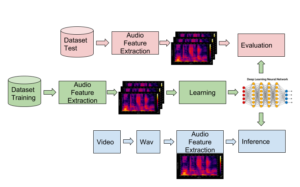 Lyra architecture for training, inference and evaluation.
Lyra architecture for training, inference and evaluation.
Given the strict protocol for subtitling imposed by the client, we have designed a second machine learning stage on top of the neural network. This stage is trained with duration information of human-generated subtitles in order to learn how humans tend to place and cut the segments. Together with explicit enforcement of subtitling rules, we obtain an optimal placing of segments. The result is a text file that serves as a template for then transcribing or translating each audio chunk.
Some performance figures
Lyra has been tested on real content in the same conditions that it is received by subtitling services (e.g. audio quality). On average we obtain a performance of 96% of correct subtitle detection with respect to human-generated versions. The probability of not detecting a subtitle where there should be one is only 2.45% and false alarms rate is 4.65%. This error corresponds mostly to presence of songs or shouts that normally are not translated thus not having a subtitle entry in the ground-truth version. In terms of time accuracy the difference of time positioning between a subtitle produced by Lyra and the “truth” is of just 4.75% on average.
Deployment of the system to a production pipeline is currently ongoing at Oxobox. First tests gave amazing results. A 90 minute program takes Lyra around 1 min 30 to process and generate the subtitle template. For subtitling projects of eight days of duration it saves two days of work.


Left Image: Original subtitle (Spanish) Right Image: Result by Lyra